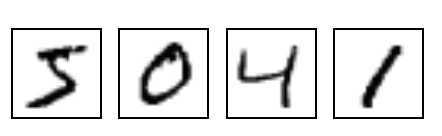
We are gonna learn how we can recognize handwritten digits by Tensorflow.
There is a dataset available for us to use. The Mnist dataset is a collection of thousands of images of 28 x 28 pixels each.
The problem is, there given image of a digit and our task is to predict which one of these.
Before jump into the coding part you better set your environment, here is how to do it.
Installing Tensorflow in ubuntu 16.04
1. Install python virtual environment by issuing below command
sudo apt-get install python-pip python-dev python-virtualenv
2. Create a virtual environment by issuing below command
virtualenv --system-site-packages targetDirectory
3. Activate the virtual environment
activate ~/targetDirectory
Now, your prompt should change to the follwoing
(tensorflow)$
if it does then, Congratulation, you've successfully installed Tensorflow
Now you better install ipython notebook, to do so execute following commands
1. sudo apt-get -y install ipython ipython-notebook 2. sudo -H pip install jupyter
To run the notebook execute 'jupyter notebook'command without quota
Now you're good to go
let's first import necessary libraries we need, import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
learn = tf.contrib.learn
tf.logging.set_verbosity(tf.logging.ERROR)
Now we do import mnist dataset
mnist = learn.datasets.load_dataset('mnist')
data = mnist.train.images
labels = np.asarray(mnist.train.labels, dtype=np.int32)
test_data = mnist.test.images
test_labels = np.asarray(mnist.test.labels, dtype=np.int32)
Good.
There are total 55k examples in our dataset, for make it faster we will only take 10k of it. max_examples = 10000; data = data[:max_examples] labels = labels[:max_examples]
before moving to the next step let's look into our dataset, to do that we need to define a function def display(i):
img = test_data[i]
plt.title('example %d label %d' % (i, test_labels[i]))
plt.imshow(img.reshape((28,28)),cmap = plt.cm.grey_r) display(0) 
it
should display exactly like thisThese
images are 28x28 pixels in grey scale also they are properly segment
that mean each image contain
exactly one digit.
To identify the image we'll use raw pixels as input so total input
we'll have 28x28 = 784 pixels
We just have to send these raw pixels as input to our classifier and
classifier will do the rest.
As there are total 784 input nodes and 9 output nodes, let's assume x0, x1, x2...xn represent
the input node and y0, y1, y2...yn represent output node.
Now the input and outputs are fully connected by the edges and each of
these edges has a weight classifier examine each pixels one by
one and recognize the picture by how white or black the portion
of the image is, as example lets suppose middle pixels of picture
of number 0 is white and middle pixels of picture of number 1 is
black, so if middle pixels are white, it is more likely the picture
is of number 0 than number 1. each time a pixel got examined each
output nodes gather evidence of image is classifying represent each
type of digits. At the end which output node will gather more evidence, it is that
number with a higher possibility and to calculate how much evidence we
have, we sum the value of the pixel density multiplied by the weights,
then we can predict that image belong to the output node.


No comments:
Post a Comment